Basic introduction to processing DHS data

Loading DHS Data
Note: This data is mocked data. Request official data from their available datasets through their website.
import geopandas as gpd
import pandas as pd
from geowrangler import dhs
dhs_household_data_path = "../data/ph.DTA"
dhs_gps_coordinates = "../data/ph_gps.shp"
dhs_df = dhs.load_dhs_file(dhs_household_data_path)
CPU times: user 11.2 ms, sys: 583 µs, total: 11.8 ms
Wall time: 10.6 ms
| 0 |
0 |
PH7 |
725 |
80 |
61 |
0 |
1 |
0 |
1 |
1 |
1 |
74 |
20 |
0 |
-168581 |
| 1 |
1 |
PH7 |
1009 |
19 |
92 |
1 |
1 |
1 |
1 |
1 |
0 |
51 |
15 |
1 |
127550 |
| 2 |
2 |
PH7 |
1072 |
91 |
58 |
1 |
1 |
0 |
1 |
1 |
1 |
26 |
5 |
0 |
32616 |
| 3 |
3 |
PH7 |
242 |
39 |
93 |
0 |
1 |
0 |
0 |
0 |
1 |
76 |
11 |
0 |
80338 |
| 4 |
4 |
PH7 |
102 |
11 |
27 |
0 |
0 |
1 |
1 |
1 |
0 |
56 |
15 |
0 |
-178758 |
Renaming columns to match
DHS files do not have uniform column names. To make analysis easier, we rename commonnly ones. Feel free to extend the config to your usecase.
ph_config = dhs.load_column_config("ph")
ph_config
{'cluster number': 'DHSCLUST',
'wealth index factor score combined (5 decimals)': 'Wealth Index',
'country code and phase': 'country code and phase',
'number of rooms used for sleeping': 'rooms',
'has electricity': 'electric',
'has mobile telephone': 'mobile telephone',
'has radio': 'radio',
'has television': 'television',
'has car/truck': 'car/truck',
'has refrigerator': 'refrigerator',
'has motorcycle/scooter': 'motorcycle',
'main floor material': 'floor',
'type of toilet facility': 'toilet',
'source of drinking water': 'drinking water'}
renamed_dhs_df = dhs_df.rename(columns=ph_config)
| 0 |
0 |
PH7 |
725 |
80 |
61 |
0 |
1 |
0 |
1 |
1 |
1 |
74 |
20 |
0 |
-168581 |
| 1 |
1 |
PH7 |
1009 |
19 |
92 |
1 |
1 |
1 |
1 |
1 |
0 |
51 |
15 |
1 |
127550 |
| 2 |
2 |
PH7 |
1072 |
91 |
58 |
1 |
1 |
0 |
1 |
1 |
1 |
26 |
5 |
0 |
32616 |
| 3 |
3 |
PH7 |
242 |
39 |
93 |
0 |
1 |
0 |
0 |
0 |
1 |
76 |
11 |
0 |
80338 |
| 4 |
4 |
PH7 |
102 |
11 |
27 |
0 |
0 |
1 |
1 |
1 |
0 |
56 |
15 |
0 |
-178758 |
Cluster Summaries
wealth_col_name = "Wealth Index"
cluster_col_name = "DHSCLUST"
summarized = (
renamed_dhs_df[[wealth_col_name, cluster_col_name]].groupby(cluster_col_name).mean()
)
summarized = summarized.reset_index()
| 0 |
3 |
-232188.0 |
| 1 |
4 |
228860.0 |
| 2 |
5 |
157620.0 |
| 3 |
6 |
40308.5 |
| 4 |
7 |
-37595.5 |
summarized.DHSCLUST.isna().sum()
summarized.DHSCLUST.isna().sum()
dhs_shp = gpd.read_file(dhs_gps_coordinates)
| 0 |
PH20XX725 |
PH |
0 |
725 |
0.409441 |
0.220510 |
POINT (0.22051 0.40944) |
| 1 |
PH20XX1009 |
PH |
0 |
1009 |
0.333693 |
0.332499 |
POINT (0.33250 0.33369) |
| 2 |
PH20XX1072 |
PH |
0 |
1072 |
0.378053 |
0.089852 |
POINT (0.08985 0.37805) |
| 3 |
PH20XX242 |
PH |
0 |
242 |
0.306277 |
0.431677 |
POINT (0.43168 0.30628) |
| 4 |
PH20XX102 |
PH |
0 |
102 |
0.535456 |
0.716025 |
POINT (0.71602 0.53546) |
survey_geo = pd.merge(summarized, dhs_shp, on="DHSCLUST")
survey_geo
| 0 |
3 |
-232188.000000 |
PH20XX003 |
PH |
0 |
0.609945 |
0.350830 |
POINT (0.35083 0.60995) |
| 1 |
4 |
228860.000000 |
PH20XX004 |
PH |
0 |
0.363843 |
0.281563 |
POINT (0.28156 0.36384) |
| 2 |
5 |
157620.000000 |
PH20XX005 |
PH |
0 |
0.715438 |
0.145014 |
POINT (0.14501 0.71544) |
| 3 |
6 |
40308.500000 |
PH20XX006 |
PH |
0 |
0.758501 |
0.628373 |
POINT (0.62837 0.75850) |
| 4 |
6 |
40308.500000 |
PH20XX006 |
PH |
0 |
0.669415 |
0.479379 |
POINT (0.47938 0.66942) |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
| 995 |
1247 |
90273.333333 |
PH20XX1247 |
PH |
0 |
0.214682 |
0.419448 |
POINT (0.41945 0.21468) |
| 996 |
1248 |
212729.500000 |
PH20XX1248 |
PH |
0 |
0.189401 |
0.152806 |
POINT (0.15281 0.18940) |
| 997 |
1248 |
212729.500000 |
PH20XX1248 |
PH |
0 |
0.563460 |
0.023900 |
POINT (0.02390 0.56346) |
| 998 |
1250 |
101508.500000 |
PH20XX1250 |
PH |
0 |
0.166465 |
0.617584 |
POINT (0.61758 0.16646) |
| 999 |
1250 |
101508.500000 |
PH20XX1250 |
PH |
0 |
0.252438 |
0.668243 |
POINT (0.66824 0.25244) |
1000 rows × 8 columns
Recalculating wealth index for a single country
features = [
"rooms",
"electric",
"mobile telephone",
"radio",
"television",
"car/truck",
"refrigerator",
"motorcycle",
"floor",
"toilet",
"drinking water",
]
# apply a threshold
dhs.apply_threshold(renamed_dhs_df, columns=features, config={"rooms": [0, 25]})
| 0 |
0 |
PH7 |
725 |
80 |
61 |
0 |
1 |
0 |
1 |
1 |
1 |
74 |
20 |
0 |
-168581 |
| 1 |
1 |
PH7 |
1009 |
19 |
92 |
1 |
1 |
1 |
1 |
1 |
0 |
51 |
15 |
1 |
127550 |
| 2 |
2 |
PH7 |
1072 |
91 |
58 |
1 |
1 |
0 |
1 |
1 |
1 |
26 |
5 |
0 |
32616 |
| 3 |
3 |
PH7 |
242 |
39 |
93 |
0 |
1 |
0 |
0 |
0 |
1 |
76 |
11 |
0 |
80338 |
| 4 |
4 |
PH7 |
102 |
11 |
27 |
0 |
0 |
1 |
1 |
1 |
0 |
56 |
15 |
0 |
-178758 |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 995 |
995 |
PH7 |
834 |
63 |
83 |
0 |
1 |
1 |
1 |
1 |
1 |
28 |
10 |
0 |
241846 |
| 996 |
996 |
PH7 |
1170 |
74 |
78 |
1 |
0 |
1 |
1 |
1 |
0 |
34 |
17 |
1 |
106424 |
| 997 |
997 |
PH7 |
762 |
81 |
14 |
1 |
1 |
0 |
1 |
1 |
0 |
83 |
12 |
1 |
246898 |
| 998 |
998 |
PH7 |
63 |
40 |
21 |
0 |
1 |
1 |
1 |
1 |
1 |
12 |
2 |
1 |
-212590 |
| 999 |
999 |
PH7 |
748 |
56 |
38 |
1 |
1 |
1 |
0 |
1 |
1 |
69 |
7 |
1 |
-10774 |
1000 rows × 15 columns
renamed_dhs_df["Recomputed Wealth Index"] = dhs.assign_wealth_index(
renamed_dhs_df[features], features
)
renamed_dhs_df.head()
| 0 |
0 |
PH7 |
725 |
80 |
61 |
0 |
1 |
0 |
1 |
1 |
1 |
74 |
20 |
0 |
-168581 |
-63.515731 |
| 1 |
1 |
PH7 |
1009 |
19 |
92 |
1 |
1 |
1 |
1 |
1 |
0 |
51 |
15 |
1 |
127550 |
8.730482 |
| 2 |
2 |
PH7 |
1072 |
91 |
58 |
1 |
1 |
0 |
1 |
1 |
1 |
26 |
5 |
0 |
32616 |
-60.121255 |
| 3 |
3 |
PH7 |
242 |
39 |
93 |
0 |
1 |
0 |
0 |
0 |
1 |
76 |
11 |
0 |
80338 |
-14.959946 |
| 4 |
4 |
PH7 |
102 |
11 |
27 |
0 |
0 |
1 |
1 |
1 |
0 |
56 |
15 |
0 |
-178758 |
-14.060453 |
Recalculating wealth index for multiple countries
dhs_ph_path = "../data/ph.DTA"
dhs_kh_path = "../data/kh.DTA"
dhs_mm_path = "../data/mm.DTA"
dhs_tl_path = "../data/tl.DTA"
ph_config = dhs.load_column_config("ph")
kh_config = dhs.load_column_config("kh")
mm_config = dhs.load_column_config("mm")
tl_config = dhs.load_column_config("tl")
dhs_ph_df = dhs.load_dhs_file(dhs_ph_path).rename(columns=ph_config)
dhs_kh_df = dhs.load_dhs_file(dhs_kh_path).rename(columns=kh_config)
dhs_mm_df = dhs.load_dhs_file(dhs_mm_path).rename(columns=mm_config)
dhs_tl_df = dhs.load_dhs_file(dhs_tl_path).rename(columns=tl_config)
cols = list(ph_config.values()) + ["country code and phase"]
merged_df = pd.concat(
[
dhs_ph_df[cols],
dhs_kh_df[cols],
dhs_mm_df[cols],
dhs_tl_df[cols],
]
)
merged_df = merged_df.fillna(0)
merged_df["Recomputed Wealth Index"] = dhs.assign_wealth_index(merged_df[features])
merged_df.head()
| 0 |
725 |
-168581 |
PH7 |
20 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
74 |
61 |
80.0 |
PH7 |
122.888238 |
| 1 |
1009 |
127550 |
PH7 |
15 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
51 |
92 |
19.0 |
PH7 |
78.430888 |
| 2 |
1072 |
32616 |
PH7 |
5 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
26 |
58 |
91.0 |
PH7 |
108.113989 |
| 3 |
242 |
80338 |
PH7 |
11 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
76 |
93 |
39.0 |
PH7 |
105.464687 |
| 4 |
102 |
-178758 |
PH7 |
15 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
56 |
27 |
11.0 |
PH7 |
45.993876 |
import matplotlib.pyplot as plt # noqa
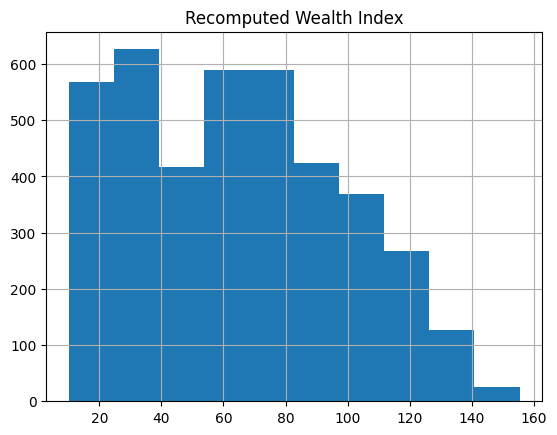
merged_df.hist("Recomputed Wealth Index")
array([[<Axes: title={'center': 'Recomputed Wealth Index'}>]],
dtype=object)
merged_df["Recomputed Wealth Index Not PCA"] = dhs.assign_wealth_index(
merged_df[features], use_pca=False
)
merged_df.head()
| 0 |
725 |
-168581 |
PH7 |
20 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
74 |
61 |
80.0 |
PH7 |
122.888238 |
-10730.578127 |
| 1 |
1009 |
127550 |
PH7 |
15 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
51 |
92 |
19.0 |
PH7 |
78.430888 |
-57116.290440 |
| 2 |
1072 |
32616 |
PH7 |
5 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
26 |
58 |
91.0 |
PH7 |
108.113989 |
30004.584457 |
| 3 |
242 |
80338 |
PH7 |
11 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
76 |
93 |
39.0 |
PH7 |
105.464687 |
-48966.528484 |
| 4 |
102 |
-178758 |
PH7 |
15 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
56 |
27 |
11.0 |
PH7 |
45.993876 |
-39722.455483 |
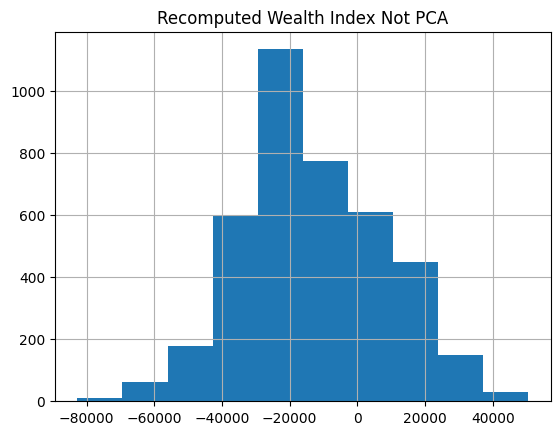
merged_df.hist("Recomputed Wealth Index Not PCA")
array([[<Axes: title={'center': 'Recomputed Wealth Index Not PCA'}>]],
dtype=object)